
CV基础学习笔记1
计算机视觉的基础知识,下游任务、卷积的原理,经典模型(如AlexNet、VGG、ResNet)、Transformer在计算机视觉中的应用(如ViT)等内容。
计算机视觉#
1.Intro#
1.1.计算机视觉任务#
- 图像分类(Image Classification):将图像分配到预定义的类别中。
- 目标检测(Object Detection):识别图像中的物体并确定其位置。
- 语义分割(Semantic Segmentation):将图像中的每个像素分配到特定的类别。
- 实例分割(Instance Segmentation):不仅区分不同类别,还区分同一类别的不同实例。
- 图像生成(Image Generation):生成新的图像。
1.2.计算机视觉发展#
计算机视觉的发展经历了从传统方法到深度学习的转变。早期的方法依赖于手工设计的特征提取技术,如SIFT和HOG。然而,随着深度学习的兴起,卷积神经网络 ( CNN ) 成为主流,如AlexNet、ResNet ,显著提升了计算机视觉任务的性能。再后来,Transformer架构也被引入计算机视觉领域,进一步推动了该领域的发展。
2.CNN#
2.1.卷积操作(Convolution Operation)#
卷积操作是CNN的核心,通过在输入图像上应用滤波器(卷积核)来提取特征。卷积操作是捕捉局部空间关系的有效方法,能够识别图像中的边缘、纹理等基本特征,低层卷积层通常捕捉简单特征,而高层卷积层则捕捉更复杂的模式和语义信息。
卷积操作的数学表达式如下:
其中,表示输入图像,表示卷积核,表示输出特征图,表示输出特征图中的位置,表示卷积核的位置。
在这里,卷积操作可以利用快速傅里叶变换(FFT) 进行加速,特别是在处理大尺寸图像时。此外,卷积操作还可以通过调整步幅(stride)和填充(padding)来控制输出特征图的尺寸。
2.2.池化操作(Pooling Operation)#
池化操作用于降低特征图的空间维度,同时保留重要信息。常见的池化方法包括最大池化(Max Pooling)和平均池化(Average Pooling)。池化有助于减少计算量,防止过拟合。
3.经典CNN架构#
3.1.AlexNet#
AlexNet使用8层可训练层,其中包括5 层卷积层 + 3 层全连接层,在进行池化的时候,使用最大池化,并引入了ReLU激活函数和Dropout技术。
3.2.VGG#
VGG网络通过使用多个连续的3x3卷积核来增加网络的深度,提升模型的表达能力。VGG网络通常使用最大池化来降低特征图的尺寸。
3.3.ResNet#
ResNet引入了残差连接(skip connections),解决了深层网络训练中的梯度消失问题。残差连接允许梯度直接流过网络。ResNet使用批量归一化(Batch Normalization)来加速训练过程,并提高模型的稳定性。
4.Transformer在计算机视觉中的应用#
4.1.ViT (Vision Transformer)#
ViT将图像划分为固定大小的patches,把每个patch当成token来处理,类似于NLP中的词嵌入。ViT使用Transformer架构,仅使用transformer的编码器,使用多头自注意力机制
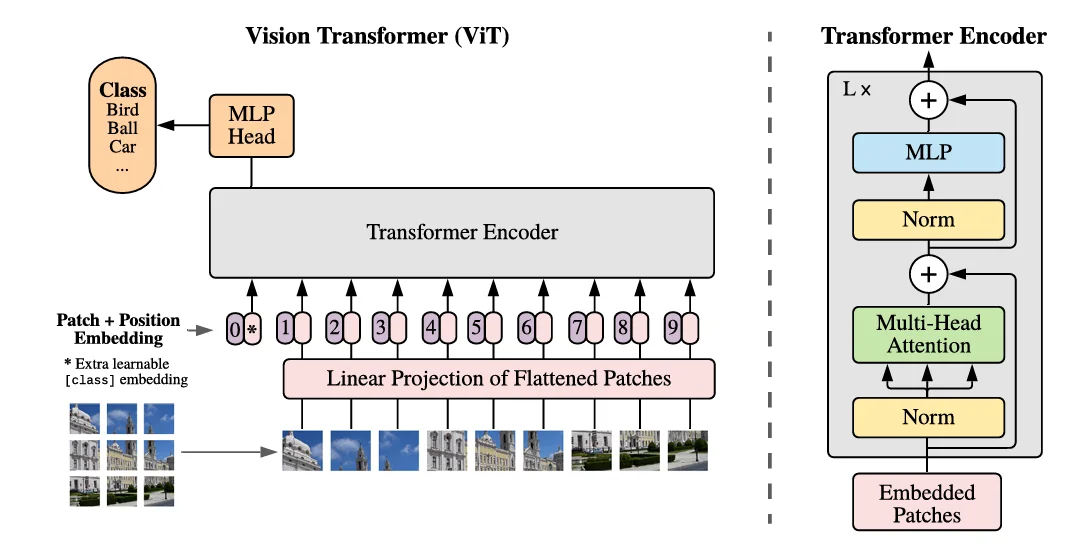
vit的基本流程:
-
图像被划分为16x16的patches,每个patch被展平并映射到一个固定维度的向量空间,即每个patch对应一个patch embedding。(这一映射过程通过可训练的线性投影(trainable linear projection)实现),然后加上一个分类令牌(class token),用于最终的分类任务。
-
然后进行位置编码(Position Encoding),vit中的位置编码是通过可学习的位置嵌入实现的。先初始化一个与patch数量相同的可学习位置嵌入矩阵。
-
位置编码被添加到patch embeddings中,以保留空间信息。
-
这些patch embeddings被输入到标准的Transformer编码器中进行处理。
-
最终的分类是通过在Transformer输出上添加一个MLP分类头来实现的。
ViT 输入输出尺寸(ViT-Base/16)
原始图像(224×224×3)→ Patches(196×768)→ Patch Embeddings(196×768)→ 加分类令牌(197×768)→ 加位置嵌入(197×768)→ 编码器输出(197×768)→ 全局表示(1×768)→ 分类结果(1×1000)