
1. 一些基本概念#
1.1 PAC#
PAC(Probably Approximately Correct)概率近似正确:
假设有一个变量,一个表示真实的函数值,假设有一个学习算法,它从样本集中学习一个假设函数来近似。我们希望在给定的误差范围和置信度下,算法能够以高概率(至少)输出一个假设函数,使得其与真实函数值的误差不超过。
总的来说就是我们希望能够以很高的概率得到一个很好的模型!!!
1.2 基本术语#
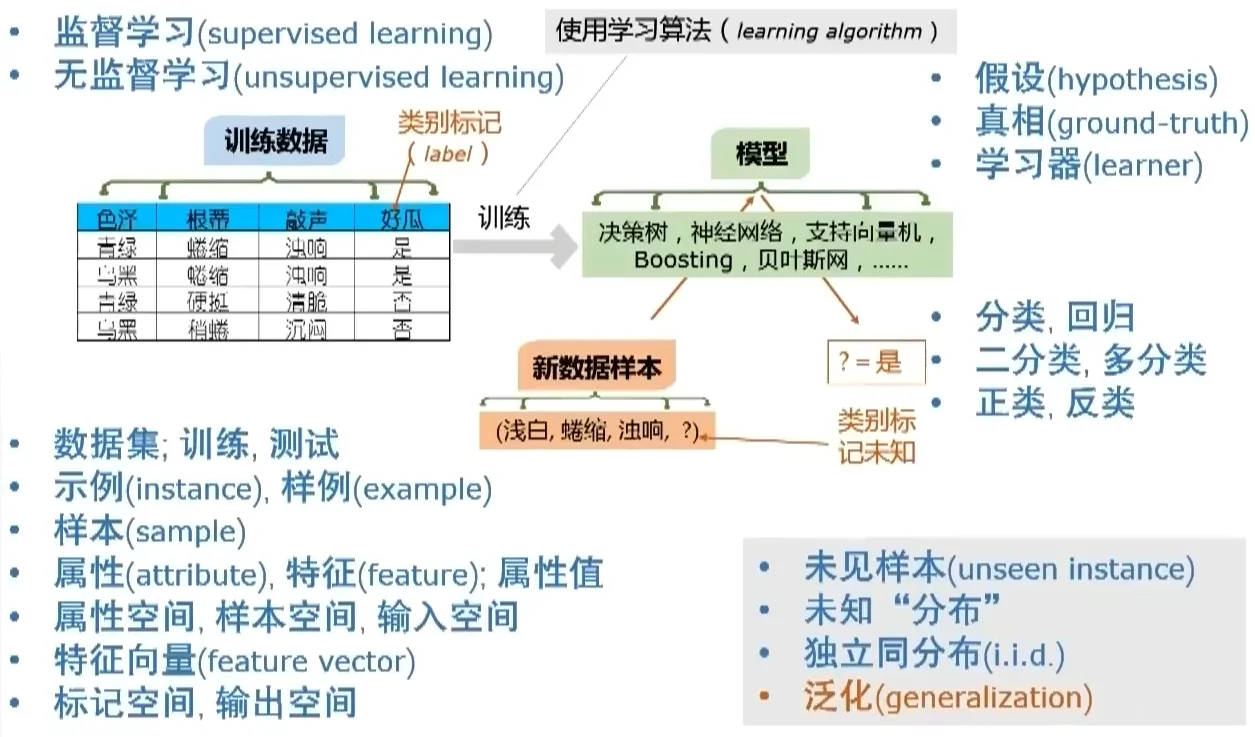
归纳偏好(Inductive Bias): 机器学习算法在学习过程中对某种类型假设的偏好,使用奥卡姆剃刀准则(Occam’s Razor Principle),即在多个假设中,选择最简单的假设。
NFL定理(No Free Lunch Theorem): 没有一种学习算法在所有可能的问题上都表现最好。不同的算法在不同的问题上可能表现不同,因此选择合适的算法需要考虑具体问题的特点,脱离具体问题谈算法没意义。
1.3模型评估#
泛化误差(Generalization Error): 衡量模型在未见过的数据上的表现。
经验误差(Empirical Error): 衡量模型在训练数据上的表现。
过拟合(Overfitting): 模型在训练数据上表现很好,但在测试数据上表现较差。
欠拟合(Underfitting): 模型在训练数据和测试数据上都表现较差。
这个算法是怎么缓解过拟合的?这种缓解的技术在什么时候会失效?
怎么获得测试集?
- 留出法(Hold-out Method): 将数据集划分为训练集和测试集。
- 交叉验证(Cross-Validation): 将数据集划分为多个子集,轮流使用一个子集作为测试集,其余子集作为训练集。
- 自助法(Bootstrap Method): 从数据集中有放回地抽取样本,构建多个训练集和测试集。但是这种方法改变了数据分布。包外估计。
调参
- 权重参数是通过训练数据学习得到的,而超参数则需要通过验证集来调节。那这么看来验证集好像是必要的。
性能度量
-
回归任务:均方误差(MSE)、平均绝对误差(MAE)等。
-
分类任务:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数等。F1 分数
混淆矩阵(Confusion Matrix)可以更好地理解分类模型的性能。,表示如下:
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
等价表示为
当我们对精确率与召回率有不同偏好的时候,可以使用加权的Fβ分数来调整它们的权重:
等价表示为
当时,召回率的权重更大,此时我的模型更加希望能够捕捉到更多的正样本; 当时,精确率的权重更大,此时我的模型更加希望预测为正样本的样本中真正为正样本的比例更高。
比较检验
假设检验(Hypothesis Testing)是一种统计方法,用于比较两个或多个模型的性能是否存在显著差异。常用的方法包括t检验(t-test)、McNemar检验(基于列联表,卡方检验)。
2.线性模型#
找到一个线性函数来使得。
最小二乘法(Ordinary Least Squares, OLS): 通过最小化预测值与真实值之间的平方误差来估计模型参数。
损失函数为:,
其中为样本数量,为第个样本的特征向量,为第个样本的真实值。
找到一个极值点,这个极值点意味着可能为极大值点/极小值点,而在线性回归中,可以无限大,因此这个极值点就是极小值点。(哇哦!!!)
若不可逆,可以使用正则化方法来解决。
3.决策树#
决策树是一种树状结构的模型,用于分类和回归任务。它通过递归地将数据划分为更小的子集来构建树状结构,每个节点表示一个特征的测试,每个分支表示测试结果的不同取值,每个叶节点表示最终的预测结果。
划分条件:
信息增益(Information Gain): 选择能够最大化信息增益的特征进行划分。信息增益衡量了通过划分数据集所获得的信息量。划分公式如下:
其中表示数据集的熵,表示特征,表示特征的所有可能取值,表示在特征上取值为的子集。(老师讲过,没复习之前竟然一点印象都没有,看到才例子想起来讲过,悲~)
增益率(Gain Ratio):选择能够最大化增益率的特征进行划分。增益率是信息增益与特征固有值的比值,是为了解决信息增益偏向于选择取值较多的特征的问题。(比如有一个手机号特征,这肯定不一样,决策树就可能变成了一个菊花图) 划分公式如下
其中表示特征的固有值,计算公式为:
基尼指数(Gini Index): 选择能够最小化基尼指数的特征进行划分。基尼指数衡量了数据集的纯度,值越小表示数据集越纯。划分公式如下:
其中表示类别的数量,表示类别在数据集中的比例。
剪枝
剪枝是为了防止过拟合,通过减少决策树的复杂度来提高模型的泛化能力。常用的剪枝方法包括预剪枝和后剪枝。
缺失值处理
样本赋权,权重划分
停止条件:
- 所有样本属于同一类别。
- 达到预设的树的最大深度。
- 当前节点包含的样本为空或少于预设的最小样本数。
4.支持向量机(SVM,上课未讲)#
支持向量机是一种用于分类和回归任务的监督学习算法。它通过寻找一个最优的超平面来将不同类别的样本进行分离。支持向量机的目标是最大化类别之间的间隔。
如果原始空间是有限维,则可以通过核函数将数据映射到高维空间,从而使得数据在高维空间中线性可分。
5.神经网络基础#
略
6.贝叶斯分类器#
贝叶斯分类器是一种基于贝叶斯定理的概率分类算法。贝叶斯决策理论为了最小化分类错误率,应该选择后验概率最大的类别作为预测结果。给定个类别,对于一个新的样本,贝叶斯分类器通过计算每个类别的后验概率来进行分类。根据贝叶斯定理,后验概率可以表示为:,其中是似然概率,表示在类别下观察到样本的概率;是先验概率,表示类别在总体中的比例;是样本的边际概率。
- 判别式模型与生成式模型
判别式模型直接建模后验概率,如决策树;生成式模型则建模联合概率,如朴素贝叶斯分类器。

- 极大似然估计
先假设某种概率分布,然后基于训练数据来估计该分布的参数, 对与训练集中类别的样本,极大似然估计的目标是找到参数,使得在给定类别的条件下,观察到训练数据的概率最大化。数学表达式如下:,其中的,其中表示训练集中属于类别的样本集合。但是在实际应用中,直接计算似然函数可能会导致数值下溢,因此通常使用对数似然函数进行优化,数学表达式如下:。
朴素贝叶斯分类器(Naive Bayes Classifier)
朴素贝叶斯分类器是一种基于贝叶斯定理的简单而有效的分类算法。它假设特征之间是条件独立的,即在给定类别的条件下,特征之间相互独立。尽管这个假设在实际应用中可能不成立,但朴素贝叶斯分类器在许多任务中表现良好。
重点在于计算似然概率,根据条件独立性假设,可以将其分解为各个特征的条件概率的乘积:,其中表示特征的数量,表示第个特征。
-
估计先验概率:可以通过计算训练集中每个类别的样本数量与总样本数量的比例来估计先验概率。数学表达式:,其中表示类别的样本数量,表示训练集中的总样本数量。
-
估计条件概率:对于离散特征,就是好瓜中根蒂是蜷缩的概率,就是这种特征在该类别下出现的频率。数学表达式:,其中表示在类别下特征取值的样本数量,表示类别的样本数量。
-
拉普拉斯修正:为了解决零概率问题,可以使用拉普拉斯修正(Laplace Smoothing)来调整条件概率的估计。数学表达式:,其中表示在类别下特征取值的样本数量,表示类别的样本数量,表示特征的可能取值数量。
7.集成学习#
好而不同!!!
同质的主要是要有差异性,异质的输出做比较时要做Alignment(配准)。(这里说的是模型类型是否相同,比如三个CNN属于同质的)
7.1 Boosting#
Boosting是确定一个基学习方法,多个基学习器,使用之前的训练集进行测试,根据测试结果调整样本权重,错误分类的样本权重增加,正确分类的样本权重减少,然后使用调整后的样本权重重新训练基学习器。最终将多个基学习器的预测结果进行加权投票或加权平均,得到最终的预测结果。(背后的统计学-残差最小化)
7.2 Bagging#
Bagging是Bootstrap Aggregating的缩写,是一种通过有放回地抽样来构建多个训练集的方法。每个基学习器在不同的训练集上进行训练,最终将多个基学习器的预测结果进行投票或平均,得到最终的预测结果。
这个的改进版本就是随机森林了。
8.聚类#
聚类是一种无监督学习方法,用于将数据集划分为多个簇,使得同一簇内的数据点相似度较高,而不同簇之间的数据点相似度较低。常用的聚类算法包括K均值聚类(K-Means Clustering)、层次聚类(Hierarchical Clustering)和密度聚类(Density-Based Clustering)等。
8.1距离度量#
- 非负性: 距离度量的值必须是非负的,即,对于任意的和。
- 对称性: 距离度量必须满足对称性,即,对于任意的和。
- 三角不等式: 距离度量必须满足三角不等式,即,对于任意的、和。
- 同一性: 距离度量必须满足同一性,即当且仅当。
8.2原型聚类#
原型聚类是一种基于原型的聚类方法,通过定义每个簇的中心点(原型)来进行聚类。常用的原型聚类算法包括K均值聚类(K-Means Clustering)和高斯混合模型(Gaussian Mixture Model, GMM)等。
K均值聚类(K-Means Clustering)