
9.Scaling Law basics#
9.1 data与performance的关系#
可以用一个公式来表示数据量与模型性能的关系:
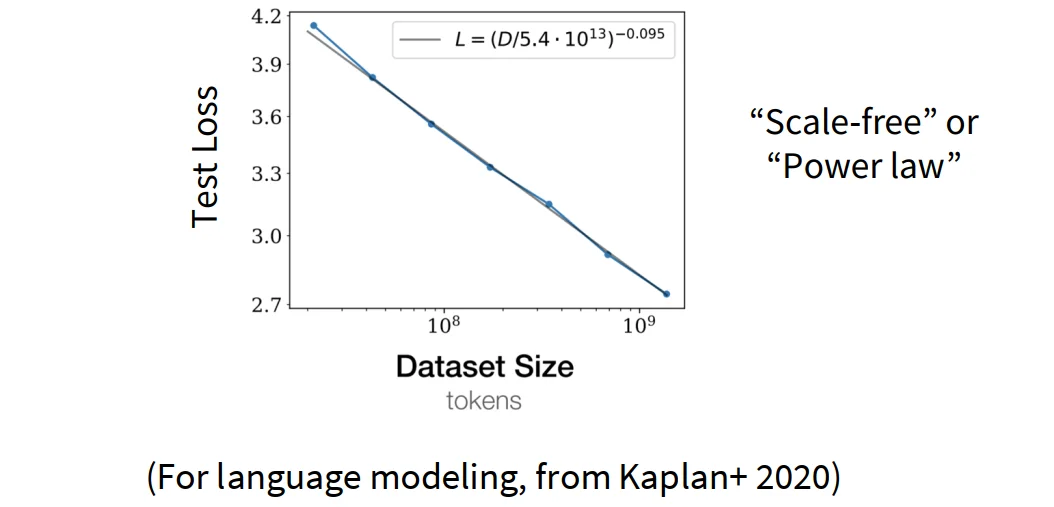 假设有个样本,然后这些样本服从高斯分布,即,如果使用来估计,那么估算的均方误差。
然后两边取个log,于是,误差的对数与数据量的对数成线性关系。这就是一种scaling law。从这里可以认识到任何像这样的关系都可以被看作是一种scaling law。
假设有个样本,然后这些样本服从高斯分布,即,如果使用来估计,那么估算的均方误差。
然后两边取个log,于是,误差的对数与数据量的对数成线性关系。这就是一种scaling law。从这里可以认识到任何像这样的关系都可以被看作是一种scaling law。
9.2 data 与 model size的关系#
在进行模型构建时选择哪些呢?
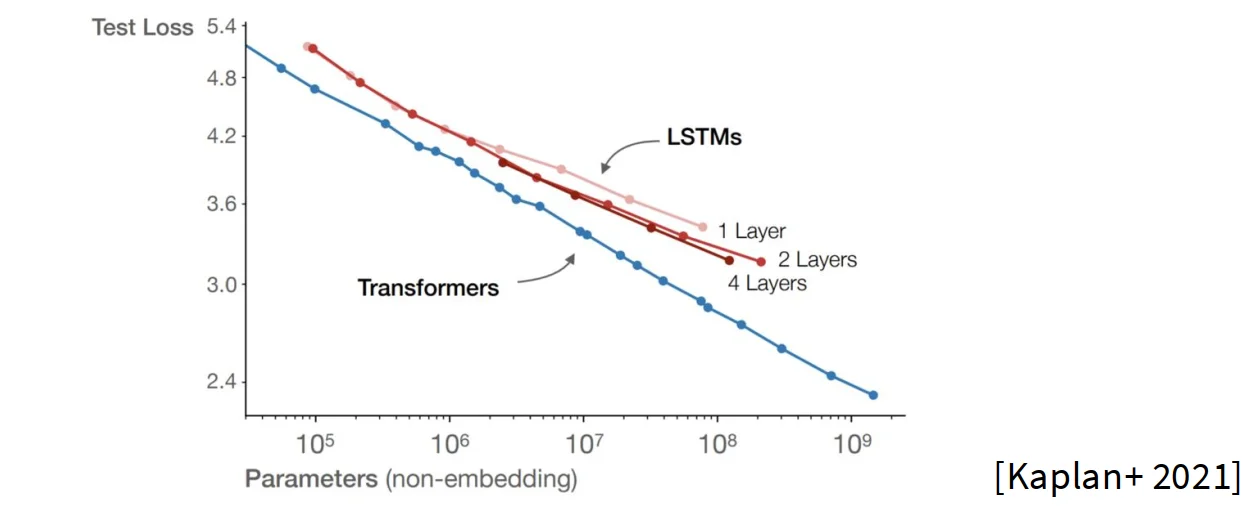
架构
对比不同的架构,发现transformer与LSTM,可以从下面的图中看到结果
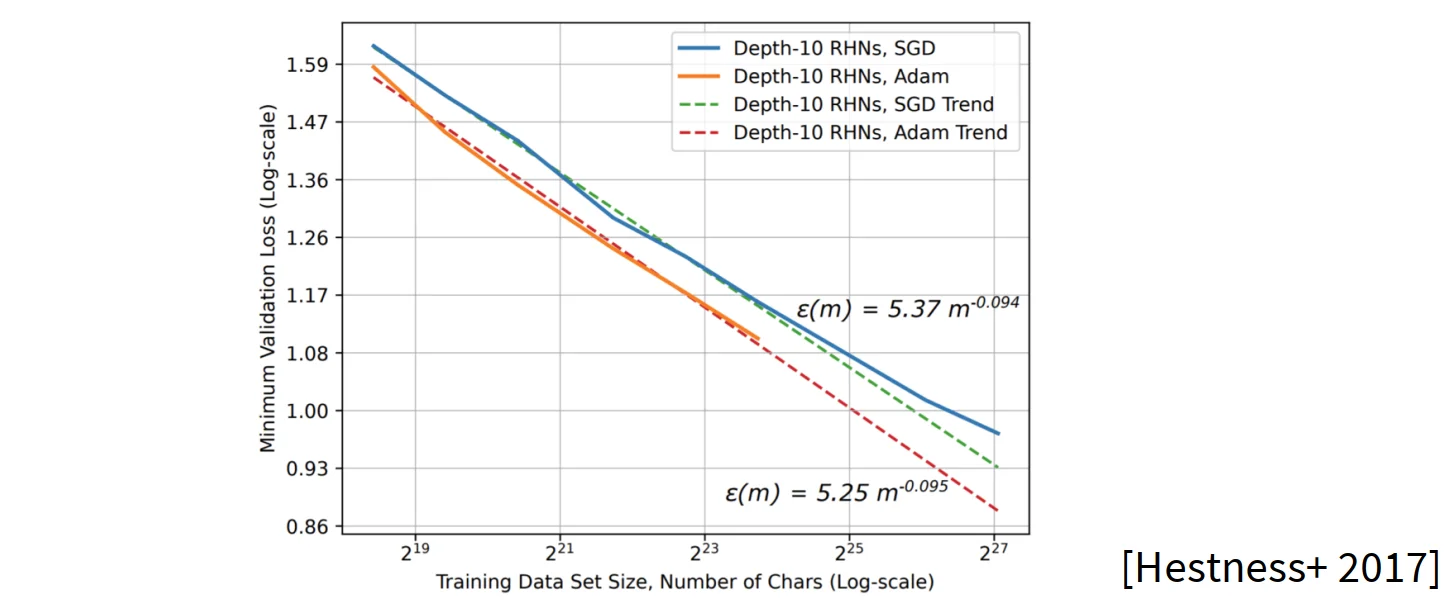
优化器
对比不同的优化器,如Adam与SGD,可以从下面的图中看到结果,
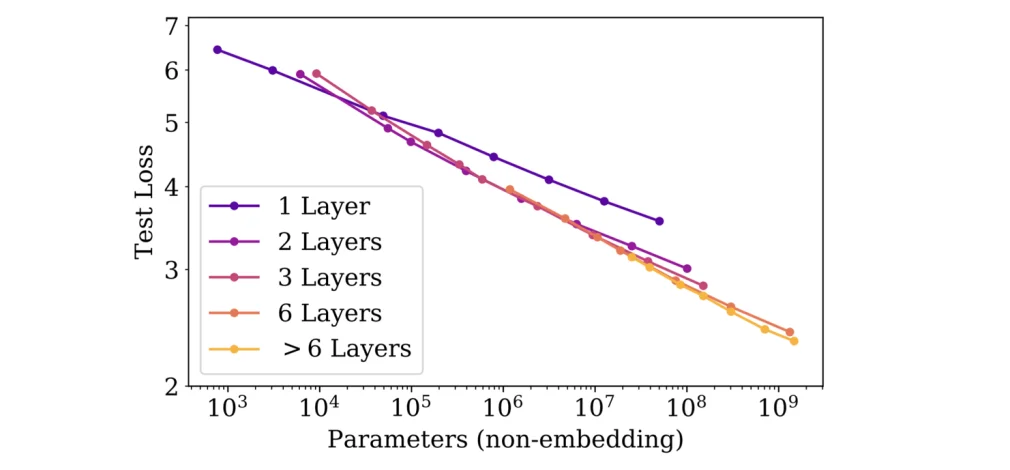
width vs depth
对比不同的宽度与深度,可以从下面的图中看到结果,当然在实际使用中还需要考虑计算成本与时间成本等因素,
9.3 hyper-parameter与performance的关系#
batch size
batch size的影响如下图所示:
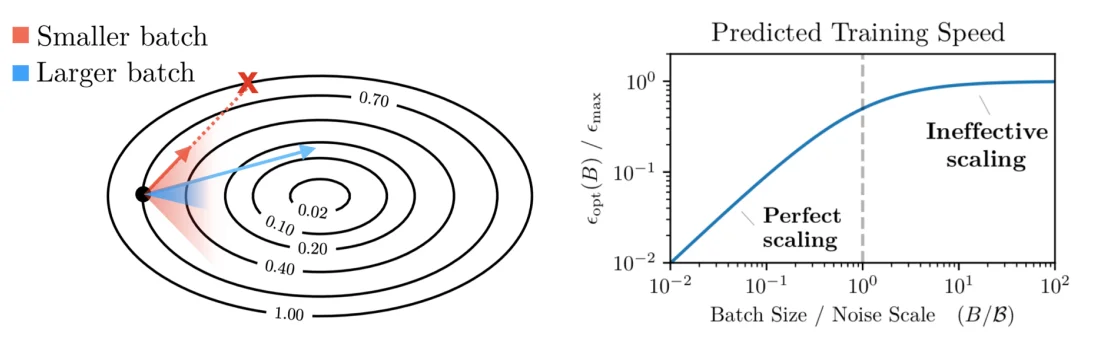 通过左图可以看出来小 batch 的梯度方向不稳定,路径带有更多噪声,大 batch 的梯度更接近真实方向,路径更直,更稳定。然后但每一步计算成本更高。
通过左图可以看出来小 batch 的梯度方向不稳定,路径带有更多噪声,大 batch 的梯度更接近真实方向,路径更直,更稳定。然后但每一步计算成本更高。
右图中的Noise Scale可以认为是训练中 “噪声刚好被压到可接受水平” 的那个最小批量大小。于是右图的含义就是训练速度与batch size的关系。
然后可以定义临界批量大小 = 达到目标损失所需的最小样本数 / 达到目标损失所需的最小步数
learning rate
当模型宽度缩放时,最优学习率也会变化。,因此可以采用mup等方法来进行,当模型缩放时,学习率按固定规律缩放。
9.4 data与model size的数学关系#
Joint data-model scaling law可以表示为:
也有研究表明可以表示为下面的式子,基本上是等价的,差了一个常数项,这个代表某个不可降低的最低误差C: